Vision Transformer (ViT) trong Nhận diện Hình ảnh
Vision Transformer (ViT) là gì?
Các mô hình Transformer có phải là một phương pháp học sâu hay không?
Kiến trúc Vision Transformer (ViT)

Vào năm 2022, Vision Transformer (ViT) nổi lên như một giải pháp thay thế cạnh tranh so với các mạng thần kinh tích chập (Convolutional Neural Network, gọi tắt là CNN) vốn đang là ứng dụng tiên tiến trong thị giác máy tính, và được sử dụng rộng rãi trong các tác vụ nhận dạng hình ảnh khác nhau. Các mô hình ViT được đánh giá là vượt trội hơn so với CNN gần 4 lần về hiệu quả tính toán và độ chính xác.
Các mô hình Transformer từ trước đến nay đã trở thành nền tảng của rất nhiều mô hình khác, tạo ra một bước ngoặt lớn trong lĩnh vực Xử lý ngôn ngữ tự nhiên (NLP). Trong nghiên cứu thị giác máy tính, ngày càng có nhiều sự quan tâm dành cho Vision Transformer (ViT) – một loại mô hình Transformer.
Vậy Vision Transformer (ViT) là gì, và nó được ứng dụng và vận hành trong nhận diện hình ảnh như thế nào? Bài viết sau đây sẽ mang đến bạn câu trả lời chi tiết.
Trong khi mô hình Transformer đã trở thành tiêu chuẩn cho các tác vụ liên quan đến Xử lý ngôn ngữ tự nhiên (NLP), thì các trường hợp sử dụng nó trong thị giác máy tính (Computer Vision) vẫn chỉ là một con số ít ỏi. Trong thị giác máy tính, Cơ chế Attention sẽ hoặc được sử dụng kết hợp với các mạng nơ-ron tích chập (CNN), hoặc được sử dụng để thay thế các khía cạnh nhất định của CNN.
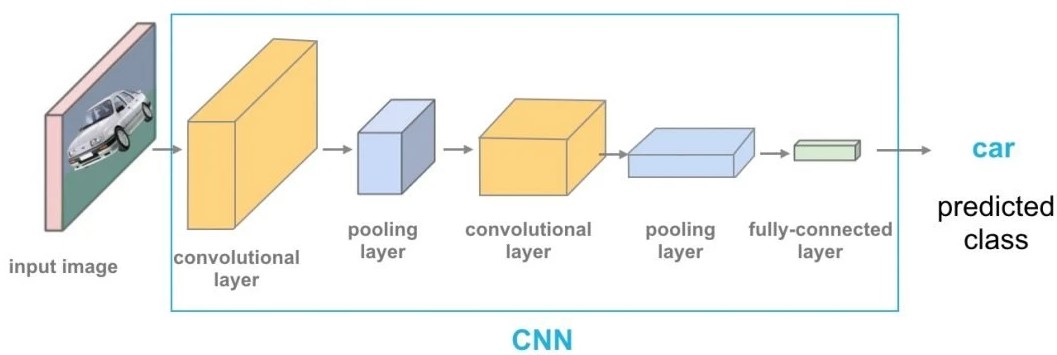
Tuy nhiên, sự phụ thuộc này vào CNN là không bắt buộc, và một mô hình Transformer thuần túy được áp dụng trực tiếp vào chuỗi các mảng hình ảnh (image patch – là một hình chữ nhật chứa nhiều điểm ảnh gần nhau, đủ lớn để có thể chứa được các bộ phận có thể mô tả được vật thể trong ảnh), sẽ có thể vận hành đặc biệt tốt trong các nhiệm vụ phân loại hình ảnh.
Gần đây, Vision Transformers (ViT) đã đạt được hiệu suất cạnh tranh cao cho một số ứng dụng thị giác máy tính, chẳng hạn như phân loại hình ảnh, phát hiện đối tượng và phân vùng hình ảnh từ một tập các lớp được định nghĩa trước.
Mô hình Vision Transformer (ViT) đã được giới thiệu trong một bài báo nghiên cứu được xuất bản dưới dạng báo cáo hội nghị tại ICLR 2021, có tiêu đề “An Image is Worth 16*16 Words: Transformers for Image Recognition in Scale”. Nó được phát triển và xuất bản bởi Neil Houlsby, Alexey Dosovitskiy, và 10 tác giả khác của Google Research Brain Team.
Mã tinh chỉnh và các mô hình ViT đã pre-trained (tạm dịch: tiền huấn luyện) hiện có sẵn trên GitHub của Google Research. Quá trình pre-train này được tiến hành qua bộ dữ liệu ImageNet và ImageNet-21k.
Transformer trong học máy là một mô hình học sâu sử dụng các cơ chế của Cơ chế Attention, cân nhắc kỹ lưỡng tầm quan trọng của từng phần dữ liệu đầu vào. Transformer trong học máy bao gồm nhiều lớp Cơ chế Self-attention, chủ yếu được sử dụng trong các lĩnh vực AI của xử lý ngôn ngữ tự nhiên (NLP) và thị giác máy tính (CV).
Transformer trong học máy sở hữu những tiềm năng đầy hứa hẹn về một phương pháp học tập tổng quát có thể được áp dụng cho các phương thức dữ liệu khác nhau trong thị giác máy tính, nhằm đạt được độ chính xác tiêu chuẩn hiện đại với hiệu quả tham số tốt hơn.
ViT đạt được kết quả đáng chú ý hơn CNN, trong khi dùng ít tài nguyên tính toán hơn cho pre-training. Nhìn chung, so với CNN, ViT có xu hướng quy nạp yếu hơn, dẫn đến sự phụ thuộc ngày càng nhiều vào việc điều chỉnh mô hình (model regularization) hoặc tăng dữ liệu (AugReg) khi pre-train trên các tập dữ liệu nhỏ hơn.
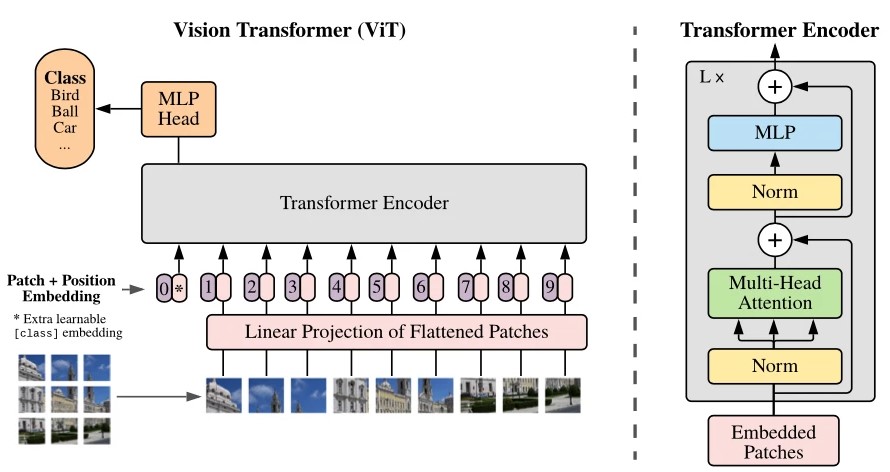
ViT là một mô hình trực quan dựa trên kiến trúc của một kiến trúc Transformer ban đầu được thiết kế cho các tác vụ dựa trên văn bản. Mô hình ViT chuyển hình ảnh đầu vào thành một loạt các mảng hình ảnh, và dự đoán trực tiếp các nhãn lớp cho hình ảnh. ViT cho thấy một hiệu suất phi thường khi được huấn luyện trên đủ dữ liệu, vượt xa hiệu suất của một CNN hiện đại tương tự với tài nguyên tính toán ít hơn 4 lần.
Những kiến trúc Transformer này có tỷ lệ thành công cao trong mô hình NLP và hiện cũng được áp dụng cho hình ảnh và các nhiệm vụ nhận dạng hình ảnh. CNN sử dụng mảng pixel, trong khi ViT chia hình ảnh thành các tokens trực quan. Transformer trực quan chia hình ảnh thành các mảng hình ảnh có kích thước cố định, mã hóa từng mảng theo thứ tự làm đầu vào cho Transformer encoder. Hơn nữa, các mô hình ViT vượt trội hơn CNN gần bốn lần về hiệu quả tính toán và độ chính xác.
Lớp Self-attention trong ViT có khả năng tổng hợp thông tin trên toàn bộ hình ảnh. Mô hình này cũng học trên dữ liệu huấn luyện để mã hóa vị trí tương đối của các mảng ảnh nhằm tái tạo lại cấu trúc của hình ảnh.
Transformer encoder bao gồm:
- Lớp Multi-Head Self Attention (MSP): Lớp này nối tất cả các kết quả đầu ra của Cơ chế Attention một cách tuyến tính theo đúng kích thước. Nhiều Attention head sẽ giúp huấn luyện những yếu tố phụ thuộc cục bộ và toàn bộ trong một hình ảnh.
- Lớp Multi-Layer Perceptrons (MLP): Lớp này chứa một hàm Gaussian Error Linear Unit hai lớp.
- Lớp thường: Lớp này được thêm vào trước mỗi khối, vì nó không bao gồm bất kỳ yếu tố phụ thuộc mới nào giữa các hình ảnh huấn luyện. Điều này giúp cải thiện thời gian đào tạo và hiệu suất tổng thể.
Hơn nữa, các residual connections được tính vào sau mỗi khối vì chúng cho phép các thành phần đi qua mạng lưới trực tiếp mà không đi qua những hàm kích hoạt phi tuyến tính.

Ảnh gốc (bên trái) và bản đồ Attention của mô hình ViTS/16 (bên phải). Nguồn: Cornell University
Cơ chế Attention, cụ thể hơn là Self-attention, là một trong những yếu tố thiết yếu của mô hình Transformer. Nó là một phép toán sơ khai được sử dụng để định lượng các tương tác thực thể theo từng cặp, giúp một mạng lưới tìm hiểu cấu trúc phân cấp và sự liên kết hiện diện bên trong dữ liệu đầu vào. Cơ chế Attention đã được chứng minh là yếu tố then chốt để mạng lưới tầm nhìn đạt được độ bền cao hơn.

Bản đồ Attention của ViT được trực quan hóa trên hình ảnh từ ImageNet-A. Nguồn: Cornell University
Kiến trúc tổng thể của mô hình ViT được đưa ra như sau theo cách thức từng bước:
Trong khi kiến trúc ViT đầy đủ là một lựa chọn đầy hứa hẹn cho các tác vụ xử lý thị giác, hiệu suất làm việc của ViT vẫn kém hơn so với các giải pháp thay thế CNN có kích thước tương tự (chẳng hạn như ResNet) khi được huấn luyện từ đầu trên một tập dữ liệu cỡ trung như ImageNet.
Hiệu suất của ViT phụ thuộc vào các quyết định như của trình tối ưu hóa, độ sâu mạng lưới và siêu tham số cụ thể của tập dữ liệu. So với ViT, CNN dễ dàng tối ưu hóa hơn.
Một mô hình ViT thông thường sử dụng tích chập 16*16 với stride 16. Trong khi đó, tích chập 3*3 với stride 2 làm tăng độ ổn định và nâng cao độ chính xác.
CNN chuyển đổi các điểm ảnh cơ bản thành một bản đồ đặc trưng. Sau đó, bản đồ đặc trưng được một trình mã hóa thành một chuỗi các tokens, rồi được nhập vào kiến trúc Transformer đó. Mô hình này sau đó áp dụng cơ chế chú ý để tạo ra một chuỗi các tokens đầu ra. Cuối cùng, 1 lớp projector kết nối các tokens đầu ra với bản đồ đặc trưng. Điều này vì vậy giúp làm giảm số lượng tokens cần được học, giảm chi phí đáng kể.
Đặc biệt, nếu mô hình ViT được huấn luyện trên bộ dữ liệu khổng lồ có trên 14 triệu hình ảnh, nó có thể hoạt động tốt hơn CNN. Nếu không, lựa chọn tốt nhất là gắn vào ResNet hoặc EfficientNet. Mô hình ViT được huấn luyện trên một tập dữ liệu khổng lồ trước khi quá trình tinh chỉnh. Thay đổi duy nhất là bỏ qua lớp MLP và thêm một lớp D lần KD * K mới, trong đó K là số lớp của tập dữ liệu nhỏ.
Mô hình ViT sử dụng Multi-Head Self Attention trong lĩnh vực Thị giác máy tính mà không cần đến hình ảnh về một đồ vật cụ thể. Mô hình này chia hình ảnh lớn ra thành một loạt các mảng hình ảnh nhỏ hơn và được nén lại thành vector theo vị trí của ảnh, sau đó được đưa vào Transformer encoder. Khi làm như vậy, Transformer encoder học được những đặc tính tổng quát và chi tiết có trong ảnh. Cuối cùng, ViT không những có độ chính xác cao hơn trên những dataset lớn, mà còn giảm lượng thời gian cần thiết để huấn luyện mô hình.
Thông tin chi tiết vui lòng liên hệ:
Địa chỉ: 192 Lê Trọng Tấn - Hà Nội
Số điện thoại: 098 913 8873
Email: [email protected]
