Công nghệ
05 kiến trúc mạng bạn nên biết về thị giác máy tính

Để giải quyết một cách linh hoạt và thuần thục các bài toán về thị giác máy tính, việc hiểu rõ và nắm chắc các kiến trúc mạng chính là yếu tố nền tảng. Do đó, trước khi bắt tay vào thực chiến các dự án nguồn mở, bạn cũng nên “nhẩm lại” kiến thức về các kiến trúc mạng dành cho thị giác máy tính.
Còn nếu bạn đã vội quên và đang cần hệ thống lại kiến thức, FriData tuần này sẽ là cứu cánh. Dưới đây là tóm tắt 05 kiến trúc mạng mà mọi kỹ sư về Thị giác máy tính cần phải biết. Hãy bỏ túi ngay và cùng chia sẻ tới các anh em “trong ngành” nhé!
Danh mục
Convolutional Neural Networks (CNN)
Ý tưởng về tích chập lần đầu tiên được giới thiệu bởi Kunihiko Fukushima trong bài báo về Neocognitron. Neocognitron đã giới thiệu 2 loại lớp, lớp convolutional và lớp downsampling. Sau đó, nghiên cứu quan trọng tiếp theo thuộc về nhóm của Yann LeCun khi sử dụng lan truyền ngược (back-propagation) để tìm hiểu các hệ số của kernel tích chập từ hình ảnh. Điều này giúp tự động hóa quá trình học tập, loại bỏ các thao tác thủ công tốn nguồn lực. Tiếp đến, bài báo “Phân loại ImageNet với Mạng nơ-ron tích chập sâu” vào năm 2012, của Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton, được nhiều người coi là bài báo có ảnh hưởng nhất về mạng nơ-ron tích chập. Họ đã tạo ra Alexnet và giành chiến thắng trong cuộc thi Imagenet 2012.
Về cơ chế, các neural networks thông thường được đào tạo trên các lớp tính toán WX + b, trong đó W là ma trận trọng số được học thông qua lan truyền ngược, các mạng thần kinh tích chập sử dụng các trọng số được gọi là bộ lọc.
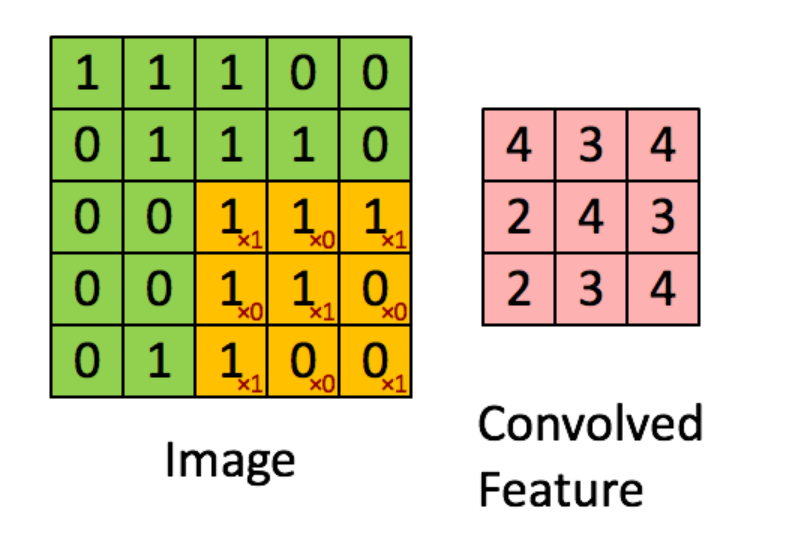
Kernel tích chập hoặc bộ lọc tựa như một cửa sổ trượt trên ma trận đầu vào. Trong hình ảnh trên, bộ lọc là ma trận màu cam với các số màu đỏ. Ma trận đầu vào là ma trận màu xanh lá cây với các số màu đen. Ở mỗi giai đoạn, bộ lọc được nhân với phần chồng chéo của phần tử ma trận đầu vào và các giá trị được tính tổng. Kết quả thu được là đầu ra đầu tiên. Hàm loss có thể được tính toán cho đầu ra và nhãn đối với các giá trị bộ lọc, và với lan truyền ngược, ta có thể tìm các giá trị đó.
Nhìn chung, CNN mạnh vì hai lý do chính:
- Chúng có số lượng tham số trên mỗi lớp ít hơn đáng kể và do đó có thể được xếp chồng lên nhau để tạo thành các lớp sâu hơn.
- Chúng giải quyết vị trí của đầu vào. Vị trí của các pixel trong một hình ảnh được duy trì, vì kernel hoạt động trên các phần của hình ảnh tại một thời điểm, vị trí tương đối của các pixel được duy trì. Điều này khác với các mạng truyền thống không tính đến vị trí.
Residual Networks (ResNet)
ResNet được giới thiệu bởi nhóm nghiên cứu Kaiming He trong bài báo có sức ảnh hưởng lớn “Deep Residual Learning for Image Recognition”. Bài viết của nhóm nghiên cứu Microsoft đã giành chiến thắng trong cuộc thi Imagenet 2015.
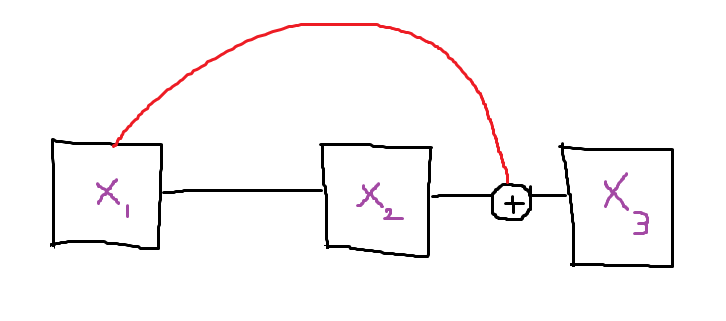
Kết nối nhảy cách (Skip connections)
sNets xuất phát từ một ý tưởng cực kỳ đơn giản nhưng thông minh. Đó là thêm các skip connections hoặc shortcut connections nhằm cho phép các gradient chảy tốt hơn trong các bước lùi, cũng như tăng đáng kể độ hội tụ, thời gian đào tạo và giảm hiện tượng gradient explosion/vanishing.
U-Nets
U-Nets được giới thiệu bởi Olaf Ronneberger, Philipp Fischer và Thomas Brox trong bài báo “U-Net: Convolutional Networks for Biomedical Image Segmentation”. Bài báo năm 2015 này là một cuộc cách mạng cho phân đoạn hình ảnh. Phân đoạn hình ảnh là nhiệm vụ gán nhãn cho từng , pixel trong một hình ảnh với danh mục của nó.
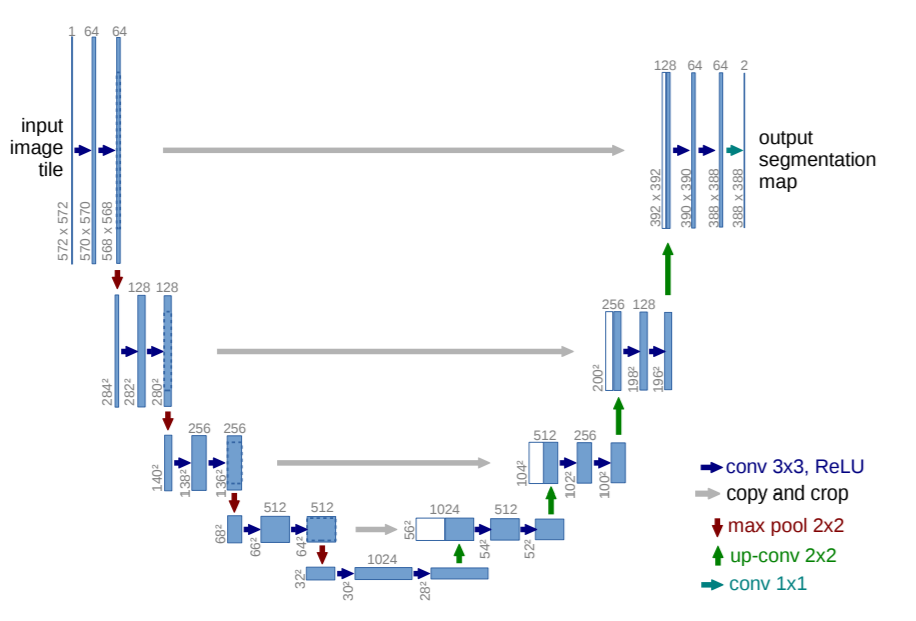
Kiến trúc U-Net
U-Nets có 2 phần, contracting path (downsampling path) và expansive path (upsampling path). Trong một mạng tích chập phân loại hình ảnh truyền thống, hình ảnh được đưa vào một mạng thực hiện các hoạt động tích chập và tổng hợp, cả hai đều làm giảm chiều cao và chiều rộng nhưng tăng độ sâu của đầu ra. Với sự mất mát về chiều cao và chiều rộng, độ sâu thu được sẽ bổ sung các đặc trưng cho đầu ra phân loại.
Tuy nhiên, trong các tác vụ phân đoạn, ta cần đầu ra có cùng hình dạng với hình ảnh đầu vào và các đặc trưng bổ sung để gán nhãn pixel. Vì vậy, quá trình downsampling của kiến trúc Conv truyền thống được bổ sung bằng upsampling path, để thêm lại chiều cao và chiều rộng của hình ảnh vào đầu ra, trong khi vẫn duy trì các đặc trưng khác. Có nhiều phương pháp upsampling, nhưng phương pháp phổ biến nhất được sử dụng trong hầu hết các thư viện là Transpose convolution upsampling. Bạn có thể đọc về phương pháp này tại đây.
You Only Look Once (YOLO)
YOLO lần đầu tiên được giới thiệu bởi Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi trong bài báo “You Only Look Once: Unified, Real-Time Object Detection”. Kết quả nghiên cứu được đánh giá là một mô hình hiện đại, nhanh chóng để phát hiện đối tượng vào năm 2015.
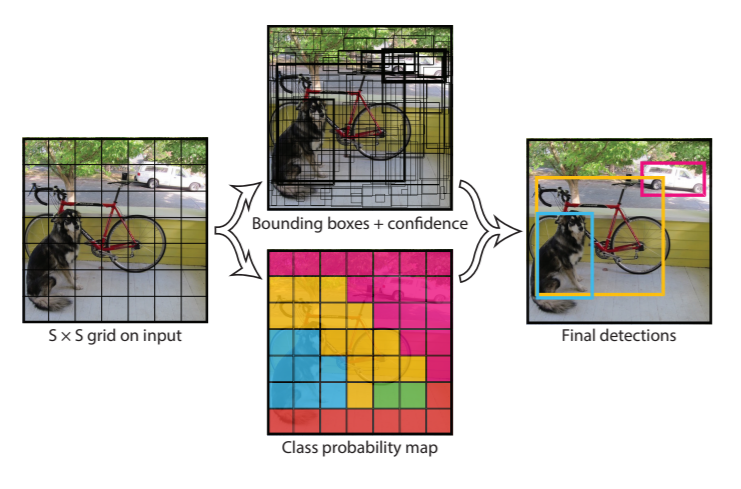
Kiến trúc của YOLO
YOLO là viết tắt của you only look once. Khi bài báo được phát hành, phương pháp phổ biến để phát hiện đối tượng là sử dụng lại bộ phân loại để phân loại các vùng cục bộ của hình ảnh và sử dụng phương pháp cửa sổ trượt (sliding window) để kiểm tra xem mỗi vùng của hình ảnh có đối tượng hay không. YOLO đã thay đổi mô hình bằng cách đề xuất phát hiện đối tượng dưới dạng bài toán hồi quy, trong đó chỉ sử dụng một mạng duy nhất cho toàn bộ đường ống và xử lý toàn bộ hình ảnh cùng một lúc thay vì theo vùng.
YOLO chia hình ảnh đầu vào thành lưới SxS. Và đối với mỗi lưới dự đoán xem tâm của một đối tượng có nằm trong lưới hay không. Nếu tâm của đối tượng nằm trong lưới, thì lưới sẽ dự đoán một hộp giới hạn có 5 giá trị, x,y,w,h,c. (x,y) là tọa độ của tâm đối tượng so với lưới, (w,h) là chiều rộng và chiều cao của đối tượng so với toàn ảnh và (c ) là lớp của đối tượng.
YOLO có 3 lợi ích chính, bao gồm:
- Tốc độ cực kỳ nhanh, sử dụng hồi quy nên không cần một quy trình phức tạp.
- Dự đoán dựa trên suy luận về toàn bộ hình ảnh. Không giống như các kỹ thuật dựa trên đề xuất theo vùng và cửa sổ trượt, YOLO quan sát toàn bộ hình ảnh trong thời gian đào tạo và đánh giá, nên nó ngầm mã hóa thông tin theo ngữ cảnh về các lớp cũng như sự xuất hiện của chúng.
- Học các biểu diễn khái quát hóa của các đối tượng. Vì YOLO có tính khái quát cao nên ít có khả năng bị lỗi khi áp dụng cho các miền mới hoặc đầu vào không mong muốn.
Generative adversarial networks (GAN)
>Generative adversarial networks hay gọi tắt là GAN đã được giới thiệu bởi Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio trong bài báo “Generative Adversarial Networks”.
.png)
Mô hình mạng GAN
GAN là một cặp mạng thần kinh được đào tạo thông qua một quy trình đối nghịch. 2 phần của GAN là Generator và Critic/Discriminator. Vai trò của Generator là tạo dữ liệu chất lượng cao tương tự như dữ liệu huấn luyện và vai trò của Discriminator là phân biệt giữa dữ liệu được tạo và dữ liệu thực. Chức năng mục tiêu của Generator là tối đa hóa tổn thất của Discriminator và chức năng của Discriminator là giảm thiểu tổn thất của nó.
Có rất nhiều ứng dụng cho GAN, trong đó hai ứng dụng cực kỳ thú vị là:
Super-resolution: Siêu phân giải đề cập đến việc chụp một hình ảnh chất lượng thấp và tạo ra một hình ảnh chất lượng cao từ nó. DLSS mới của Nvidia có thể sử dụng kỹ thuật này. Jeremey Howard từ fast.ai có một phương pháp cực kỳ thú vị được gọi là phương pháp noGAN cho siêu phân giải. Quá trình này là một loại đào tạo trước cho GAN, trong đó hình ảnh chất lượng cao được chuyển đổi thành hình ảnh chất lượng thấp hơn cho dữ liệu đào tạo của Generator và Discriminator được đào tạo trước về hình ảnh. Bằng cách này, cả Generator và Discriminator đều có một khởi đầu thuận lợi và phương pháp này được cho là cải thiện đáng kể thời gian đào tạo cho GAN.
Deep fakes: Deep fakes cũng là GAN nơi Generator được đào tạo để thực hiện thao tác giả mạo và Discriminator có nhiệm vụ phát hiện giả mạo. Discriminator có thể được đào tạo đủ lâu để đánh lừa hầu hết con người. Đây là một công nghệ tồn tại nhiều rủi ro, đang gây tranh cãi và cần lưu ý trên internet.
Thông tin chi tiết vui lòng liên hệ:
Công ty Cổ phần tư vấn giải pháp Công nghệ CSTSOFT
Địa chỉ: 192 Lê Trọng Tấn - Hà Nội
Số điện thoại: 098 913 8873
Email:support@cstsoft.net
