
Trí tuệ nhân tạo (AI) và khoa học máy tính (CS) cho phép các hệ thống tự động xử lý hình ảnh và video theo cách tương tự con người để phát hiện và xác định các đối tượng hoặc khu vực quan trọng, dự đoán kết quả hoặc thậm chí thay đổi hình ảnh sang hình dạng, màu sắc,.. mong muốn. Các ứng dụng phổ biến của thị giác máy tính bao gồm hệ thống nhận diện hình ảnh cho xe tự lái, thực tế ảo và tăng cường (AR,VR) cho các mô phỏng, trò chơi, kính mắt, trải nghiệm bất động sản và thương mại điện tử…
Mặt khác, quá trình xử lý hình ảnh y tế (MI) liên quan đến việc phân tích chi tiết hình ảnh y tế như MRI, CT hoặc X-quang để phát hiện bệnh lý tự động. Hầu hết các trường hợp sử dụng phổ biến trong lĩnh vực MI bao gồm gán nhãn (chẩn đoán) bệnh lý tự động, khoanh vùng tổn thương, liên kết với điều trị hoặc tiên lượng và y học cá nhân hóa.
Với tiềm năng phát triển mạnh và ứng dụng rộng rãi, thị giác máy tính và xử lý ảnh y tế hiện đang là hai lĩnh vực cực “hút” người học. Tuy nhiên, chỉ đọc các nghiên cứu thôi chưa đủ, các “newbie” cần trau dồi kĩ năng “thực chiến”, đơn giản nhất thông qua những dự án nguồn mở, hoàn toàn miễn phí và có sẵn trên Internet.
Bài viết dưới đây sẽ gợi ý top 6 dự án dành cho người mới bắt đầu trong lĩnh vực CV và MI, đồng thời cung cấp các ví dụ với dữ liệu và source code để bắt đầu, cũng như hướng dẫn giải chi tiết để giúp bạn tự học hiệu quả hơn.
Đừng quên lưu lại và chia sẻ với các anh em để cùng luyện tập nhé! Các dự án đã được phân loại theo cấp độ từ dễ đến khó, giúp bạn dễ dàng lựa chọn và tự đánh giá năng lực bản thân.
Mục tiêu: Xử lý hình ảnh (X) có kích thước [28×28] pixel và phân loại chúng thành một trong 10 nhóm(class) đầu ra (Y). Đối với tập dữ liệu MNIST, hình ảnh đầu vào là các chữ số viết tay trong khoảng từ 0 đến 9. Tập dữ liệu huấn luyện và kiểm tra lần lượt chứa 60.000 và 10.000 hình ảnh được dán nhãn (phân loại sẵn). Lấy cảm hứng từ vấn đề nhận dạng chữ số viết tay, một bộ dữ liệu khác có tên là bộ dữ liệu Fashion MNIST đã được tạo ra với mục tiêu là phân loại hình ảnh (có kích thước [28×28]) thành các danh mục quần áo như trong Hình 1.

Hình 1: Bộ dữ liệu MNIST và Fashion MNIST với 10 loại đầu ra mỗi loại.
Phương pháp: Khi hình ảnh đầu vào nhỏ ([28×28] pixel) và hình ảnh có thang độ xám, các mô hình mạng thần kinh (neuron) tích chập (CNN), trong đó số lớp tích chập có thể thay đổi từ một lớp đến nhiều lớp là các mô hình phân loại phù hợp. Một ví dụ về xây dựng mô hình phân loại MNIST bằng Keras được trình bày trong tệp MNIST colab
Một ví dụ khác về phân loại trên bộ dữ liệu Fashion MNIST được hiển thị trong: tệp Fashion MNIST Colab
Trong cả hai trường hợp, các tham số chính cần điều chỉnh bao gồm số lớp, dropout, optimizer (ưu tiên Adaptive optimizers), learning rate và kích thước kernel như tại đây. Vì đây là một bài toán nhiều lớp nên hàm kích hoạt ‘softmax’ được sử dụng ở lớp cuối cùng để đảm bảo chỉ có 1 nơron đầu ra có trọng số cao hơn các nơron khác.
Kết quả: Khi số lớp tích chập tăng từ 1–10, độ chính xác phân loại cũng tăng theo. Bộ dữ liệu MNIST được nghiên cứu kỹ lưỡng trong tài liệu với độ chính xác thử nghiệm trong khoảng 96–99%. Đối với bộ dữ liệu Fashion MNIST, độ chính xác của phép thử thường nằm trong khoảng 90–96%. Một ví dụ về trực quan hóa kết quả phân loại MNIST bằng các mô hình CNN được biểu diễn trong Hình 2 bên dưới.

Hình 2: Ví dụ trực quan hóa kết quả của mô hình CNN cho dữ liệu MNIST. Đầu vào được hiển thị ở góc trên cùng bên trái và đầu ra sau các lớp tương ứng được hiển thị. Kết quả cuối cùng nằm giữa 5 và 8.
Mục tiêu: phân loại các hình ảnh y tế (thu được bằng Chụp cắt lớp quang học, OCT) là bình thường, phù điểm vàng do tiểu đường (DME), Drusen, choroidal neovascularization (CNV). Tập dữ liệu chứa khoảng 84.000 ảnh huấn luyện và khoảng 1.000 ảnh kiểm thử có nhãn và mỗi ảnh có chiều rộng từ 800 đến 1.000 pixel.
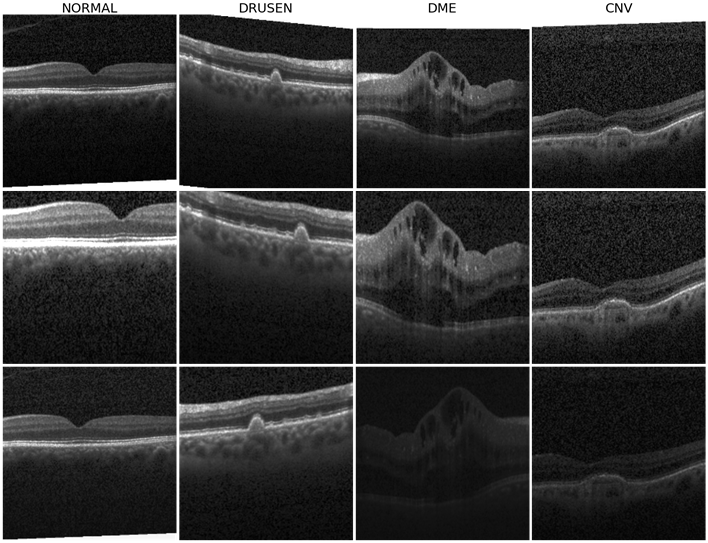
Hình 2: Ví dụ về hình ảnh OCT từ Bộ dữ liệu Kaggle
Phương pháp: Các mô hình CNN sâu như Resnet và CapsuleNet đã được áp dụng để phân loại tập dữ liệu này. Dữ liệu cần được thay đổi kích thước thành [512×512] hoặc [256×256] để làm đầu vào cho các mô hình phân loại tiêu chuẩn. Vì các hình ảnh y tế có ít sai khác hơn khi so sánh với ảnh tự nhiên ngoài trời và trong nhà, nên số lượng hình ảnh y tế cần thiết để đào tạo các mô hình CNN lớn được cho là ít hơn đáng kể so với số lượng ảnh tự nhiên. OCT Code thể hiện việc training lại các lớp ResNet trong transfer learning và phân loại các hình ảnh kiểm thử. Các tham số được tinh chỉnh ở đây bao gồm optimizer, learning rate, kích thước của hình ảnh đầu vào và số lớp kết nối toàn phần (fully-connected) ở cuối mạng ResNet.
Kết quả: độ chính xác của mô hình ResNet khi kiểm thử có thể thay đổi trong khoảng 94–99% bằng cách thay đổi số lượng ảnh training.
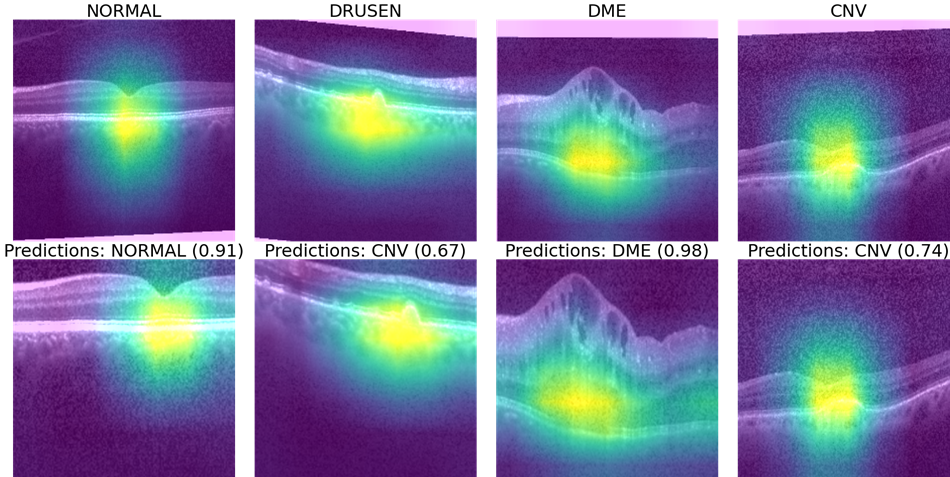
Hình 3: Các vùng quan tâm (ROI) cho từng bệnh lý được đặt chồng lên hình ảnh gốc bằng thư viện Gradcam trong python.
Những hình ảnh trực quan này được tạo bằng thư viện Gradcam kết hợp với output sau các lớp kích hoạt trong CNN chồng trên hình ảnh gốc để hiểu các vùng quan tâm hoặc các đặc trưng (feature) quan trọng được phát hiện tự động cho nhiệm vụ phân loại. Cách sử dụng Gradcam bằng thư viện tf_explain được trình bày tại đây.
Mục tiêu: Các mô hình CNN có thể hoàn thành công việc từ đầu đến cuối, nghĩa là không cần thiết kế và xếp hạng các đặc trưng (feature) để phân loại, và kết quả của mô hình là kết quả cuối cùng ta mong muốn. Tuy nhiên, điều quan trọng là phải trực quan hóa và giải thích cách hoạt động của mô hình CNN. Một số thư viện trực quan hóa và hỗ trợ phân tích mô hình phổ biến là tf_explain và Interpretable Model-Agnostic Explanations (LIME). Trong dự án này, mục tiêu là đạt được phân loại đa nhãn và giải thích những gì mô hình CNN coi là đặc trưng để phân loại hình ảnh theo một cách cụ thể. Trong trường hợp này, ta xem xét tình huống có nhiều nhãn trong đó một hình ảnh chứa nhiều đối tượng, ví dụ như mèo và chó trong Colab for LIME.
Ở đây, đầu vào là hình ảnh có mèo và chó trong đó và mục tiêu là xác định vùng nào tương ứng với mèo hoặc chó.
Phương pháp: Trong dự án này, mỗi hình ảnh được phân vùng, tức là phân chia hình ảnh thành nhiều vùng có đặc điểm và màu tương đồng nhau. Số phụ được chia có thể được chọn thủ công dưới dạng tham số. Tiếp theo, mô hình InceptionV3 được gọi để tính toán xác suất cho từng vùng superpixel nhỏ thuộc về một trong 1000 lớp mà InceptionV3 được đào tạo ban đầu. Cuối cùng, xác suất có object được sử dụng làm trọng số để fit 1 mô hình regression có thể giải thích vùng ROI tương ứng với từng lớp như trong hình bên dưới.
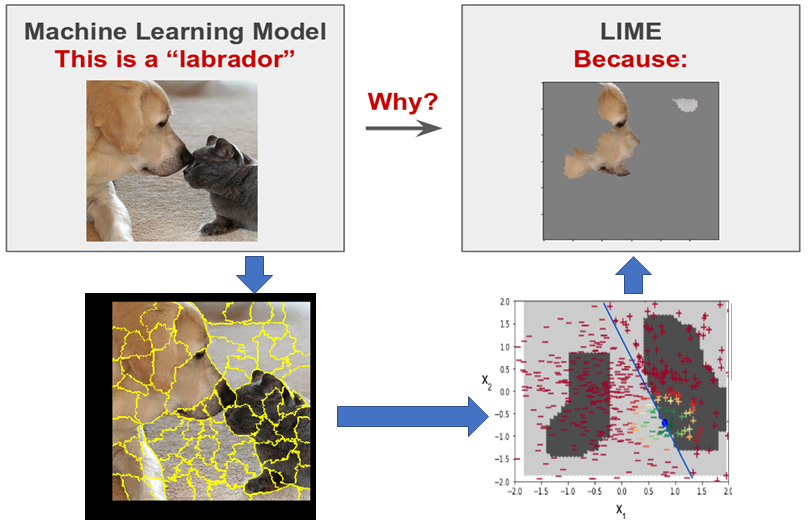
Khả năng giải thích của super-pixels bằng cách sử dụng các mô hình tương tự regression trong LIME.
Kết quả: Sử dụng phương pháp được đề xuất, vùng ROI trong hầu hết các hình ảnh phi y tế sẽ có thể giải thích được. Đánh giá định tính và khả năng giải thích như được chỉ ra ở đây đặc biệt hữu ích trong các trường hợp ngách hoặc trong các tình huống mà mô hình phân loại sai hoặc bỏ sót các đối tượng quan tâm. Trong những tình huống như vậy, việc giải thích những gì mô hình CNN đang xem xét và tăng cường các vùng ROI phù hợp để điều chỉnh hiệu suất phân loại tổng thể có thể giúp giảm đáng kể các sai lệch do bias dữ liệu gây ra.
Mục tiêu: Các mô hình CNN cho đến nay đã được áp dụng để tự động học các đặc trưng mà sau đó có thể được sử dụng để phân loại. Quá trình này được gọi là mã hóa đặc trưng. Bước tiếp theo áp dụng một bộ giải mã có cấu trúc tương tự như bộ mã hóa để cho phép tạo hình ảnh đầu ra. Sự kết hợp giữa cặp: bộ mã hóa-bộ giải mã này cho phép đầu vào và đầu ra có kích thước giống nhau, tức là đầu vào là một hình ảnh và đầu ra cũng là một hình ảnh.
Phương pháp: Sự kết hợp bộ mã hóa-bộ giải mã với các residual skip connections thường được gọi là U-net. Đối với các bài toán phân loại hai lớp và nhiều lớp, dữ liệu phải được định dạng sao cho nếu X (hình ảnh đầu vào) có kích thước [m x m] pixel, thì Y có kích thước [m x m x d], trong đó ‘d’ là số lớp được dự đoán. Các tham số để điều chỉnh bao gồm optimizer, learning rate và độ sâu của mô hình U-net như hình bên dưới.
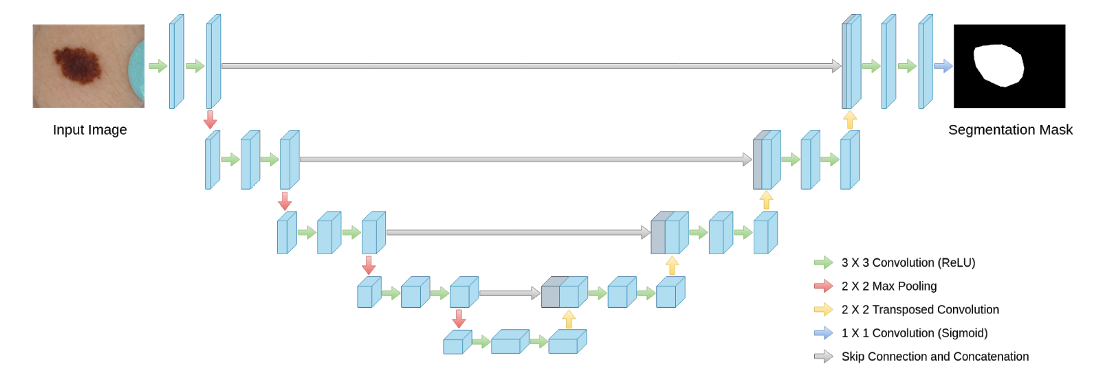
Ví dụ về mô hình U-net.
Kết quả: Mô hình U-net có thể học cách tạo semantic map 2 hoặc đa lớp từ các tập dữ liệu lớn và nhỏ, nhưng nó được cho là nhạy cảm với sự mất cân bằng dữ liệu. Do đó, việc chọn tập dữ liệu đào tạo phù hợp là rất quan trọng để có kết quả tối ưu. Các phần mở rộng khác cho công việc này sẽ bao gồm các kết nối DenseNet hoặc các mạng bao gồm bộ mã hóa-giải mã khác như mạng MobileNet hoặc Exception.
Mục tiêu: Tự động phát hiện tư thế hoặc cử chỉ thường bao gồm nhận dạng keypoint (chẳng hạn như nhận dạng cấu trúc xương) trong video có thể dẫn đến nhận dạng tư thế (đứng, đi, di chuyển) hoặc ý định của người đi bộ (sang đường, không sang đường), v.v. Đối với loại bài toán này, thông tin keyframe từ nhiều chuỗi nhỏ của các khung hình video được xử lý chung để tạo dự đoán liên quan đến tư thế/ý định.

Phương pháp: Đối với dự án này, lớp mô hình được áp dụng được gọi là “Sequence To Sequence”, trong đó một chuỗi các khung hình từ video được xử lý để dự đoán ý định của người đi bộ xem họ có định băng qua đường hay không. Quá trình bắt đầu với detector phát hiện bounding box 2D bao quanh người đi bộ, tiếp theo là tracking thời gian thực để theo dõi vị trí 1 box qua các frame. Cuối cùng, các đặc trưng từ bounding box và khung xương đã track được sử dụng để huấn luyện mô hình DenseNet dự đoán liệu người đi bộ có bước tới phía trước ô tô đang di chuyển hay không. Các tham số được điều chỉnh bao gồm các tham số của detector, số lớp của mô hình Densenet và số điểm trên khung xương để mô tả mỗi cử chỉ của người đi bộ. Số lượng điểm càng lớn thì độ phức tạp tính toán càng cao.
Kết quả: Kết quả định tính cho phương pháp trên được hiển thị trong hình bên dưới, trong đó hộp màu đỏ biểu thị người đi bộ sẽ băng qua đường so với hộp màu xanh lá cây biểu thị người đi bộ sẽ không băng qua đường với phương tiện đang tới. Các files Colab có thể được dùng để thử nghiệm các mô hình tổng hợp sử dụng các đặc trưng bên trong các bounding box và khung xương như một thiết lập ban đầu trên bất kỳ tập dữ liệu mới nào để tạo ra các dự đoán liên quan đến tư thế từ một chuỗi khung hình.

Mục tiêu: Một trường hợp sử dụng phổ biến cho các mô hình CNN là tự động tạo hình ảnh giả bằng GAN. Trong các thiết lập như vậy, hai mô hình CNN được đào tạo: 1) Trình tạo (Generator), có mục tiêu là tạo hình ảnh giống thật từ input nhiễu và một số ràng buộc, 2) Trình phân biệt (Discriminator), có mục tiêu là phân biệt hình ảnh giả và hình ảnh thật. Tập dữ liệu training yêu cầu các cặp: ảnh – semantic segmentation maps {X,Y} như trong hình và trong GAN Colab.

Các ví dụ từ Bộ dữ liệu Mặt tiền CMP trong đó semantic segmentation maps được sử dụng để dự đoán hình ảnh RGB thực tế.
Phương pháp: Đối với dự án này, thiết lập pix2pix dựa vào các conditional GAN để đào tạo Trình tạo dựa trên CNN (là mô hình U-net đã sửa đổi) nhằm tạo ra hình ảnh giả khó phân biệt/phân loại với hình ảnh thực. Các mô hình GAN thường sử dụng hàm loss là sự kết hợp của minimax loss hoặc GAN loss cùng với mean absolute error giữa hình ảnh thực và hình ảnh giả. Các tham số cần điều chỉnh bao gồm optimizer, learning rate, feature patch size (thường là 30-70 pixel mỗi chiều với PathGAN), kích thước hình ảnh đầu vào và độ phức tạp của mô hình Trình tạo.
Kết quả: Phương pháp pix2pix có thể được tận dụng để tạo ảnh màu từ ảnh xám, ảnh bản đồ từ ảnh mặt đất và ảnh RGB từ ảnh chỉ có đường nét. Mô hình này cho phép tạo dữ liệu cả ít lẫn nhiều, điều này rất quan trọng trong việc tạo thêm dữ liệu đào tạo và giải quyết “small data challenge”.
Thông tin chi tiết vui lòng liên hệ:
Công ty Cổ phần tư vấn giải pháp Công nghệ CSTSOFT
Địa chỉ: 192 Lê Trọng Tấn - Hà Nội
Số điện thoại: 098 913 8873
Email:support@cstsoft.net
