Công nghệ
Xử lý dữ liệu video bằng Học sâu trong thời gian thực

Cùng với dữ liệu hình ảnh, dữ liệu video cũng ngày một phổ biến, nhờ sự nở rộ của các loại hình livestream, vlog hay camera an ninh. Và cũng giống như xử lý hình ảnh, xử lý video sử dụng các kỹ thuật đã được thiết lập như thị giác máy tính, nhận dạng đối tượng, học máy và học sâu để tự động hóa quá trình này. Chẳng hạn, dễ dàng nhận thấy ứng dụng của thị giác máy tính và NLP trong quá trình tạo dựng và chỉnh sửa video, nhận dạng đối tượng trong các tác vụ tự động gắn thẻ nội dung video, học máy trong phân tích video AI hoặc học sâu trong việc xóa nền theo thời gian thực,…. Và không dừng lại ở đó, những ứng dụng khác của AI sẽ liên tục được phát triển để giúp con người tận dụng, khai thác tối đa giá trị của dữ liệu video.
Vậy xử lý dữ liệu video là gì? Đâu là các kỹ thuật giúp đẩy nhanh quá trình xử lý dữ liệu video? Bài viết dưới đây sẽ là một gợi mở.
Xử lý video theo thời gian thực: một số kiến thức cơ bản
Hãy bắt đầu với những điều cơ bản. Xử lý video thời gian thực là một công nghệ thiết yếu trong các hệ thống giám sát sử dụng nhận dạng đối tượng và khuôn mặt. Đây cũng là quy trình hỗ trợ phần mềm kiểm tra hình ảnh AI trong lĩnh vực công nghiệp.
Vậy thì xử lý video hoạt động như thế nào? Xử lý video bao gồm một loạt các bước, bao gồm giải mã, tính toán và mã hóa, trong đó:
- Giải mã: Quá trình cần thiết để chuyển đổi video từ tệp nén trở lại định dạng thô của nó.
- Tính toán: Một thao tác cụ thể được thực hiện trên khung video thô.
- Mã hóa: Quá trình chuyển đổi khung đã xử lý trở lại trạng thái nén ban đầu.
Bây giờ, mục tiêu của bất kỳ bài toán xử lý video nào cũng là hoàn thành các bước này nhanh nhất và chính xác nhất có thể. Và dễ dàng nhất để làm được như vậy là tiến hành xử lý song song và tối ưu hóa thuật toán về tốc độ. Điều này đồng nghĩa với việc bạn cần tận dụng tính năng tách tệp và pipeline architecture.
Tách tệp video là gì?
Việc chia nhỏ tệp video cho phép các thuật toán hoạt động đồng thời, sử dụng các mô hình chậm hơn, chính xác hơn. Điều này được thực hiện bằng cách chia video thành các phần riêng biệt và sau đó được xử lý cùng một lúc.
Bạn có thể coi việc chia nhỏ video giống như một hình thức tạo tệp ảo hơn là tạo tệp con. Mặc dù vậy, chia nhỏ tệp video không phải là lựa chọn tốt nhất để xử lý video theo thời gian thực. Bởi lẽ quá trình này khiến bạn gặp khó khăn khi tạm dừng, tiếp tục và tua lại một tệp trong khi nó đang được xử lý.
Pipeline architecture là gì?
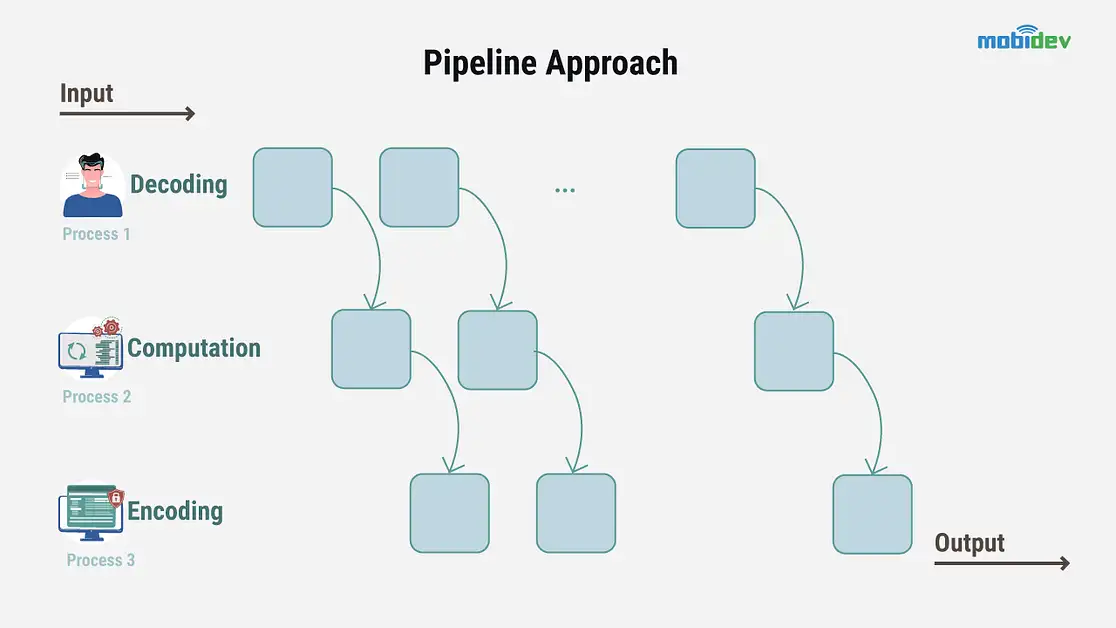
Phương pháp pipeline architecture. Nguồn ảnh: Mobidev.
Tùy chọn khác là pipeline architecture. Quá trình này hoạt động để chia nhỏ và làm song song các tác vụ đang được thực hiện trong quá trình xử lý, thay vì chia nhỏ hoàn toàn video.
Dưới đây là một ví dụ nhanh về pipeline architecture trong thực tế và cách nó có thể được sử dụng trong hệ thống giám sát video để phát hiện và làm mờ khuôn mặt trong thời gian thực.

Nguồn ảnh: KDNuggets
Trong ví dụ này, pipeline đã chia các tác vụ thành giải mã, nhận diện khuôn mặt, làm mờ khuôn mặt và mã hóa. Và nếu muốn cải thiện tốc độ của pipeline, bạn có thể sử dụng các kỹ thuật học sâu.
Còn giải mã và mã hóa thì sao? Có hai cách để bạn hoàn thành các quy trình này: dựa vào phần mềm và phần cứng.
Bạn có thể đã quen với khái niệm tăng tốc phần cứng. Quá trình này được thực hiện nhờ các bộ giải mã và mã hóa được cài đặt trong các card đồ họa NVIDIA mới nhất, cũng như các lõi CUDA.
Dưới đây là một số tùy chọn phổ biến giúp tăng tốc quá trình mã hóa và giải mã:
- Biên dịch OpenCV với hỗ trợ CUDA: Biên dịch OpenCV với CUDA tối ưu hóa cả giải mã và bất kỳ tính toán pipeline nào sử dụng OpenCV. Chú ý, ở đây, bạn cần lập trình bằng C ++ vì Python không hỗ trợ điều này.
- Biên dịch FFmpeg hoặc GStreamer với sư hỗ trợ của NVDEC / NVENC Codecs: Một tùy chọn khác là sử dụng bộ giải mã và bộ mã hóa NVIDIA tích hợp đi kèm với các cài đặt tùy chỉnh của FFmpeg và Gstreamer. Tuy nhiên, FFmpeg được khuyên dùng bởi ít yêu cầu bảo trì hơn. Ngoài ra, hầu hết các thư viện đều được cung cấp bởi FFmpeg.
- Sử dụng Khung xử lý video NVIDIA: Tùy chọn cuối cùng là sử dụng trình Python để giải mã khung trực tiếp thành bộ PyTorch trên GPU. Tùy chọn này loại bỏ việc sao chép thêm từ CPU sang GPU.
Ngoài ra, đối với các bài toán nhận diện khuôn mặt trong video, các mô hình phát hiện đối tượng (SSD hoặc RetinaFace) là một lựa chọn phổ biến. Các giải pháp này có tác dụng định vị khuôn mặt người trong khung hình. Và dựa trên kinh nghiệm của mình, các nhà phát triển thực tế có xu hướng thích các mô hình theo dõi khuôn mặt Caffe và phát hiện đối tượng TensorFlow vì chúng mang lại kết quả tốt nhất. Ngoài ra, cả hai đều có sẵn, sử dụng mô-đun dnn thư viện OpenCV.
Làm thế nào để xây dựng phần mềm xử lý video trực tiếp hỗ trợ bởi AI?
Bạn hoàn toàn có thể sử dụng codecs (một thiết bị hoặc một chương trình máy tính có khả năng mã hóa và giải mã một dòng dữ liệu hoặc tín hiệu) để xây dựng phần mềm xử lý video trực tiếp của riêng mình.
Dưới đây là ngắn gọn về những việc bạn cần làm:
- Bắt đầu bằng cách điều chỉnh mạng nơ-ron được đào tạo trước để hoàn thành các nhiệm vụ được yêu cầu.
- Định cấu hình cơ sở hạ tầng đám mây để xử lý video và mở rộng quy mô khi cần.
- Xây dựng quy định phần mềm để cô đọng quy trình và tích hợp các trường hợp sử dụng cụ thể như ứng dụng di động và quản trị viên hoặc bảng điều khiển web.
Việc phát triển một MVP cho phần mềm xử lý video tương tự có thể mất đến bốn tháng bằng cách sử dụng mạng nơ-ron được đào tạo trước và các lớp ứng dụng đơn giản. Tuy nhiên, phạm vi và tiến trình phụ thuộc vào chi tiết của từng dự án. Trong hầu hết các trường hợp, bạn nên bắt đầu với việc phát triển Proof of Concept để khám phá các chi tiết cụ thể của dự án và tìm ra một quy trình tối ưu.
Thông tin chi tiết vui lòng liên hệ:
CÔNG TY CỔ PHẦN TƯ VẤN GIẢI PHÁP CÔNG NGHỆ CSTSOFT
Địa chỉ: 192 Lê Trọng Tấn - Hà Nội
Số điện thoại: 098 913 8873
Email: support@cstsoft.net
